

The proliferation of mass-produced, AI-generated content is posing challenges for Google in identifying spam.
The presence of AI-generated content has also complicated Google’s assessment of content quality.
Nevertheless, signs indicate that Google is enhancing its capability to automatically detect low-quality AI-generated content.
Widespread Presence of Spammy AI Content on the Internet
One does not need expertise in SEO to recognize that generative AI content has infiltrated Google search results over the past year.
During this period, Google’s stance on AI-created content has evolved. The official position has transitioned from deeming it as spam that violates guidelines to prioritizing content quality over the method of content creation.
I am confident that Google’s emphasis on quality has been incorporated into numerous internal SEO presentations advocating for an AI-generated content strategy. Undoubtedly, this approach from Google provided just enough leeway to secure approval from management at various organizations.
The outcome: an abundance of AI-generated, subpar content inundating the web, with some initially surfacing in the company’s search results.
Hidden Low-Quality Content
The “visible web” represents only a fraction of the internet that search engines choose to index and display in search results.
According to Google’s Pandu Nayak, as revealed in testimony during a Google antitrust trial, Google maintains an index of approximately 400 billion documents, despite encountering trillions of documents during crawling.
This implies that Google indexes just 4% of the documents it encounters during web crawling (400 billion out of 10 trillion).
Google asserts that it filters out spam in 99% of query clicks, suggesting that it already eliminates the majority of unworthy content.
The Reign of Content and the Algorithm’s Authority
Google maintains its proficiency in evaluating content quality, although many SEOs and seasoned website managers hold contrasting views. Numerous examples showcase instances wherein inferior content outranks superior content.
A reputable company that invests in content is likely to rank among the top tier of quality content on the web. Competitors are likely to occupy similar positions. Google has already excluded numerous inferior candidates from being indexed.
Google prides itself on its achievements. With 96% of documents not making it to the index, some issues are evident to humans but challenging for machines to identify.
I have observed cases that lead to the conclusion that Google excels in recognizing which pages are “good” versus “bad” from a technical perspective, but struggles to discern between good content and great content.
Google even acknowledged this in documents presented in the DOJ’s antitrust exhibits. In a 2016 presentation, it stated, “We do not comprehend documents. We simulate it.”
A slide from a Search all-hands presentation put together by Eric Lehman
Google’s Reliance on SERP User Interactions for Assessing Content Quality
Google has traditionally relied on user interactions with Search Engine Results Pages (SERPs) to gauge the quality of document contents. As explained in a subsequent Google presentation: “Each searcher benefits from the responses of past users… and contributes responses that benefit future users.”
A slide from a Search All Hands presentation compiled by Lehman
The debate over the usage of interaction data by Google to determine content quality has persisted. It is my belief that Google predominantly uses interactions from SERPs rather than websites to make decisions regarding content quality, eliminating site-based metrics like bounce rate.
If one pays close attention to knowledgeable sources, Google has been quite transparent about employing click data in content ranking.
In 2016, Google engineer Paul Haahr delivered a presentation titled “How Google Works: A Google Ranking Engineer’s Story” at SMX West. Haahr discussed Google’s SERPs and how the search engine scrutinizes changes in click patterns. He acknowledged that this user data is “more complex to comprehend than anticipated.”
Haahr’s statement is consolidated in the “Ranking for Research” presentation slide included in the DOJ exhibits:
A slide from the “Ranking for Research” DOJ exhibit
Google’s ability to interpret user data and translate it into actionable insights hinges on discerning the cause-and-effect relationship between altering variables and their corresponding outcomes.
The SERPs represent Google’s primary domain for comprehending the prevailing variables. Interactions on websites introduce a multitude of variables beyond Google’s purview.
Even if Google could identify and quantify interactions on websites (arguably more challenging than assessing content quality), it would lead to an avalanche of distinct variable sets, each necessitating minimum traffic thresholds for meaningful deductions.
Google points out in its documents that the “growing UX complexity renders feedback progressively challenging to convert into accurate value judgments” concerning SERPs.
Brands and the Virtual Quagmire
Google asserts that the interaction between SERPs and users forms the “core mystery” behind its ability to “simulate” document comprehension.
A slide from the “Logging & Ranking” DOJ exhibit
Aside from insights offered by the DOJ exhibits, clues on how Google uses user interaction in rankings are found within its patents.
One particularly intriguing aspect is the “Site quality score,” which examines relationships such as:
- Instances where searchers include brand/navigational terms in their queries or websites incorporate them in their anchors. For instance, a search query or link anchor for “seo news searchengineland” instead of “seo news.”
- When users seem inclined to select a specific result from the SERP.
These indicators may signify that a site is an exceptionally relevant response to the query. This method of evaluating quality aligns with Eric Schmidt’s assertion that “brands offer a solution.”
This rationale corresponds with studies demonstrating users’ strong bias toward brands.
For instance, in tasks like shopping for a party dress or planning a cruise holiday, 82% of participants opted for a familiar brand, regardless of its SERP ranking, according to a Red C survey.
Brands and the associated recall they generate are costly to establish. Therefore, it is logical for Google to rely on them in ranking search results.
Identifying AI Spam According to Google
Google issued advice on artificial intelligence-created content during the current year. Its Spam Regulations explicitly describe “spammy automatically-generated content” as content produced primarily to manipulate search rankings.
Regulations regarding spam from Google
Spam is defined by Google as “Text created through automated processes without consideration for quality or user experience.” In my interpretation, this refers to anyone utilizing AI systems to generate content without a human quality assurance process.
There may be situations where an AI system is trained on confidential or private data. It might be programmed to produce more predictable outcomes to decrease errors and inaccuracies. One could argue that this is quality assurance beforehand. It is likely an infrequently utilized strategy.
All other instances I shall refer to as “spam.”
Producing this type of spam was formerly restricted to individuals with the technical expertise to extract data, construct databases for madLibbing, or employ PHP to generate text utilizing Markov chains.
ChatGPT has democratized spam with a few prompts and a simple API, along with OpenAI’s loosely enforced Publication Policy, which specifies:
“The involvement of AI in shaping the content is overtly disclosed in a manner that any reader could not easily overlook, and which a typical reader would comprehend sufficiently.”
Publication Policy from OpenAI
The volume of AI-generated content being circulated on the internet is vast. A Google Search for “regenerate response -chatgpt -results” reveals tens of thousands of pages with AI-generated content crafted “manually” (i.e., without utilizing an API).
In numerous instances, the quality assurance has been so substandard that the “authors” left in the “regenerate response” from the older versions of ChatGPT during their copy and paste operations.
Patterns observed in AI content considered spam
When GPT-3 emerged, I was intrigued by how Google would respond to unedited AI-generated content, so I established my initial test website.
This is what transpired:
- Acquired a new domain and configured a basic WordPress installation.
- Scraped information regarding the top 10,000 games selling on Steam.
- Inputted these games into the AlsoAsked API to extract the queries raised about them.
- Utilized GPT-3 to fabricate responses to these questions.
- Formulated FAQPage schema for each question and response.
- Retrieved the URL of a YouTube video about the game for embedding on the page.
- Utilized the WordPress API to generate a page for each game.
There were no advertisements or other revenue-generating features on the website.
The entire process consumed a couple of hours, and I had a fresh 10,000-page website with some Q&A content related to popular video games.
Performance data from Google Search Console for this website presented by Lily Ray at PubCon
Results of the experiment:
- Approximately 4 months later, Google chose not to display certain content, resulting in a 25% decline in traffic.
- A month subsequent, Google ceased directing traffic to the website.
- Bing continued to refer traffic throughout the entire period.
What intrigued me the most? Google did not seem to have taken manual action. There were no notifications in Google Search Console, and the two-step loss in traffic led me to doubt any manual interference.
I have observed this trend frequently with purely AI-generated content:
- Google lists the site.
- Traffic is quickly directed with consistent growth week after week.
- Traffic then reaches its peak, followed by a rapid decline.
Another instance is the scenario of Causal.app. In this “SEO heist,” a competitor’s sitemap was scavenged, and over 1,800 articles were authored using AI. The traffic followed the same course, rising for several months before plateauing, then a drop of around 25% succeeded by a crash that wiped out nearly all traffic.
Visibility data from SISTRIX for Causal.app
The SEO community deliberates whether this drop was a result of manual intervention due to the substantial media coverage it attracted. I speculate that the algorithm was at play.
Another captivating and perhaps more intriguing study involved LinkedIn’s “collaborative” AI articles. These AI-generated articles crafted by LinkedIn encouraged users to “collaborate” in the form of fact-checking, corrections, and supplements. The most active contributors were rewarded with a LinkedIn badge for their contributions.
As with the prior cases, traffic surged then subsided. However, LinkedIn maintained some level of traffic.
Visibility data from SISTRIX for LinkedIn /advice/ pages
This data implies that fluctuations in traffic are a product of an algorithm rather than manual interference.
Once modified by a human, a number of LinkedIn collaborative articles seemingly matched the definition of valuable content according to Google. However, others were deemed otherwise.
Possibly Google’s judgment was correct in this instance.
If it’s considered spam, why does it obtain rankings?
From what I have observed, ranking is a multi-phased process for Google. Constraints such as time, cost, and data accessibility hinder the implementation of more intricate systems.
Despite the continuous evaluation of documents, I suspect there is a delay before Google’s systems can identify low-quality content. This explains the recurring pattern: content passes an initial evaluation, only to be identified as subpar later on.
Let’s examine some supporting evidence for this assertion. Earlier in this discourse, we briefly mentioned Google’s “Site Quality” patent and how they utilize user interaction data to formulate a ranking score.
For a freshly launched site, users have not engaged with the content on the SERP. Thus, Google is unable to assess the quality of the content.
Another patent pertaining to Predicting Site Quality addresses this scenario.
Once again, in oversimplified terms, a quality score is projected for novel sites by initially obtaining a relative frequency measurement for various phrases identified on the new site.
These measurements are then correlated using a previously established phrase model derived from quality scores established from previously rated sites.
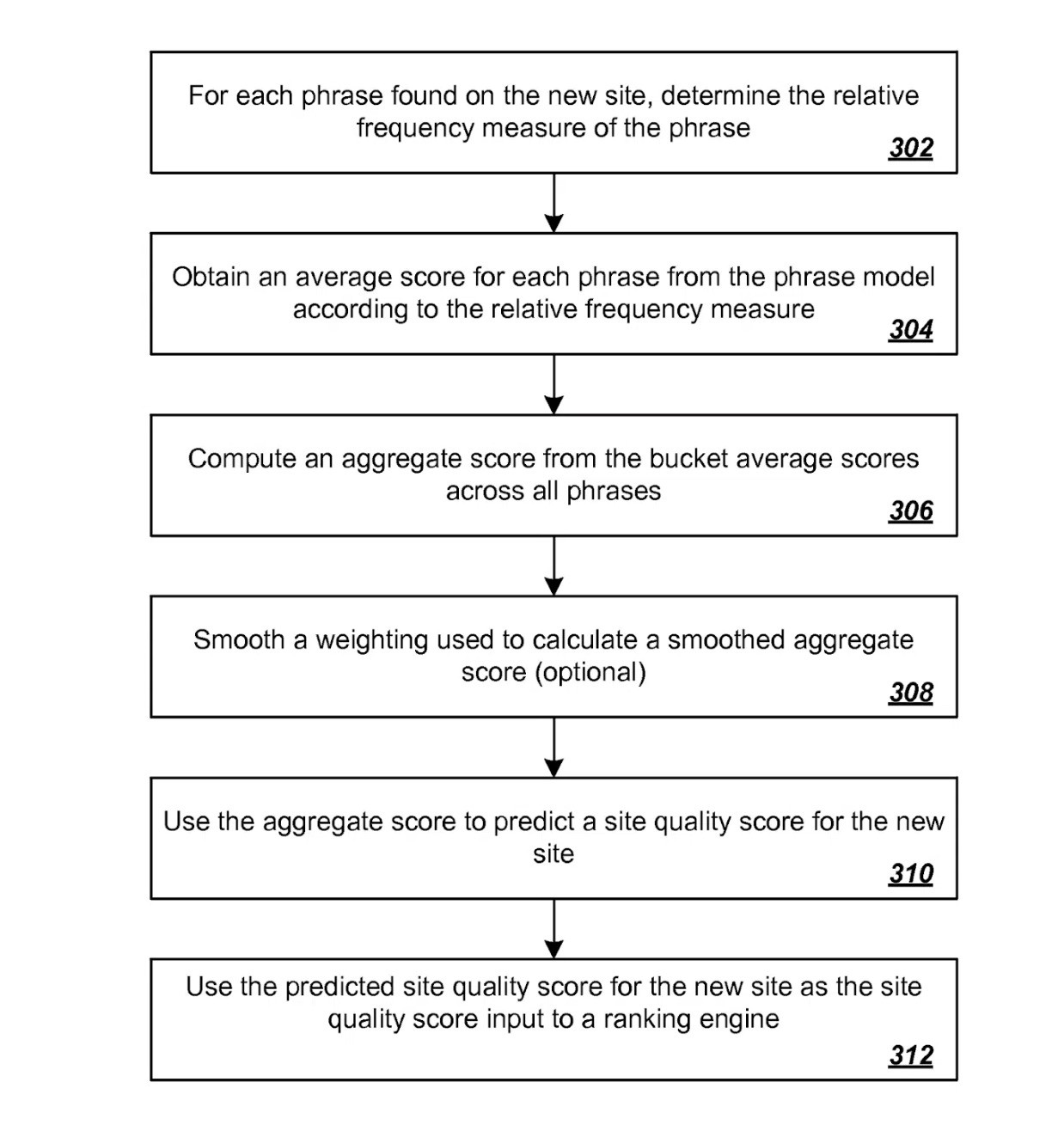
Patent for Predicting Site Quality
If Google is still employing this approach (which I believe they are, at least to some extent), it implies that numerous new websites are initially ranked based on an estimation of quality included in the algorithm. Subsequently, the ranking undergoes refinement based on user interaction data.
I and several companions have noticed that Google at times elevates sites in rankings for a preliminary evaluation phase.
Our hypothesis at that time was that an assessment was conducted to determine if user interaction aligned with Google’s projections. If not, traffic dwindled as fast as it surged. However, if it performed well, the site maintained a decent position in the SERP.
Several of Google’s patents reference “implicit user feedback,” including this forthright statement:
“A ranking sub-system can encompass a rank modifier engine that utilizes implicit user feedback to trigger a reordering of search results in order to enhance the final ranking presented to a user.”
AJ Kohn extensively detailed this type of data back in 2015.
It’s important to note that this is an aged patent among many. Since its publication, Google has devised numerous new solutions, like:
- RankBrain, explicitly noted for handling “new” queries for Google.
- SpamBrain, a primary tool from Google to combat webspam.
Google: Beware the gap
It is unclear to outsiders how much user/SERP interaction data would be utilized on individual sites by Google apart from the overall SERP, except for those with direct engineering knowledge at Google.
Nevertheless, it is known that modern systems like RankBrain are partially trained based on user click data.
A specific point caught my attention in AJ Kohn’s analysis of the DOJ testimony regarding these new systems. He mentions:
“References indicate moving a set of documents from the ‘green ring’ to the ‘blue ring.’ These references concern a document I have yet to locate. However, based on the testimony, it appears to illustrate how Google filters results from a large set to a smaller set where further ranking factors can be applied.”
This aligns with my theory. If a website passes the test, it transfers to a different “ring” for more advanced processing to enhance accuracy.
As it stands now:
- Google’s existing ranking systems struggle to match the pace of AI-generated content production and publication.
- Gen-AI systems generate grammatically correct and mostly coherent content, passing Google’s initial tests and ranking until further assessment is conducted.
Here lies the issue: the continuous generation of content with generative AI means there is a never-ending queue of sites awaiting Google’s initial evaluation.
Is HCU the solution against GPT through UGC?
I suspect Google acknowledges this as a significant challenge they must overcome. Speculatively, recent updates like the Helpful Content Update (HCU) could have been implemented to address this vulnerability.
It is known that HCU and “hidden gems” systems have benefited user-generated content (UGC) platforms like Reddit.
Reddit, an already highly visited site, saw its search visibility more than double due to recent Google modifications, at the expense of other sites.
My theory is that UGC platforms, with some exceptions, are less likely sources of mass-produced AI content due to content moderation.
While not perfect search results, the overall satisfaction of browsing raw UGC may surpass Google consistently ranking whatever ChatGPT generates online.
The emphasis on UGC could be a temporary remedy to bolster quality as Google struggles to combat AI spam promptly.
How will Google tackle AI spam in the long run?
During the DOJ trial, much of the testimony concerning Google came from Eric Lehman, a former 17-year employee who worked as a software engineer at Google focusing on search quality and ranking.
A recurring theme in Lehman’s claims was the increasing importance of Google’s machine learning systems, BERT and MUM, surpassing user data. These systems are becoming so potent that Google may rely more on them than on user data in the future.
With slices of user interaction data, search engines possess a reliable proxy for decision-making. The challenge lies in gathering sufficient data quickly enough to keep up with changes, which is why some systems incorporate alternative methods.
If Google can enhance their models using breakthroughs like BERT to significantly improve the accuracy of their initial content analysis, they may bridge the gap and notably reduce the time required to detect and de-rank spam.
This issue persists and is vulnerable to exploitation. As more individuals search for effortless, high-yield opportunities, the pressure on Google to rectify its weaknesses intensifies.
Ironically, as a system becomes proficient in combating spam of a specific kind at scale, it may render itself almost redundant by diminishing the opportunities and motivations to engage in such activities.
