大量生産された AI 生成コンテンツの急増により、Google によるスパムの識別が困難になっています。
AI によって生成されたコンテンツの存在により、Google によるコンテンツ品質の評価も複雑になっています。
しかしながら、Google は AI によって生成された低品質のコンテンツを自動的に検出する機能を強化している兆候があります。
インターネット上でのスパム的な AI コンテンツの広範な存在
過去 1 年間に生成的な AI コンテンツが Google の検索結果に浸透してきたことを認識するのに、SEO の専門知識は必要ありません。
この間、Google の AI 作成コンテンツに対する姿勢は変化し、ガイドラインに違反するスパムとみなす姿勢から、コンテンツ作成方法よりもコンテンツの品質を優先する姿勢へと公式の立場は変化しました。
Google の品質重視の姿勢は、AI が生成したコンテンツ戦略を提唱する数多くの社内 SEO プレゼンテーションに取り入れられていると確信しています。Google のこのアプローチは、さまざまな組織の経営陣から承認を得るのに十分な余裕を与えたことは間違いありません。
その結果、AI が生成した低品質のコンテンツが大量に Web 上に溢れ、その一部は当初は同社の検索結果に表示されました。
隠された低品質コンテンツ
「目に見えるウェブ」は、検索エンジンがインデックスして検索結果に表示することを選択したインターネットのほんの一部にすぎません。
Google の Pandu Nayak 氏によると、Google の独占禁止法裁判での証言で明らかにされたように、Google はクロール中に何兆もの文書に遭遇したにもかかわらず、約 4,000 億の文書のインデックスを維持しています。
これは、Google が Web クロール中に遭遇するドキュメントのうち 4% (10 兆のうち 4000 億) のみをインデックスすることを意味します。
Google は、クエリ クリックの 99% でスパムをフィルター処理していると主張しており、価値のないコンテンツの大部分をすでに排除していることを示唆しています。
コンテンツの支配とアルゴリズムの権威
Google はコンテンツ品質の評価において優れた能力を維持していますが、多くの SEO と経験豊富な Web サイト管理者は対照的な見解を持っています。劣ったコンテンツが優れたコンテンツを上回る例が数多くあります。
コンテンツに投資する評判の良い企業は、Web 上の質の高いコンテンツのトップ層にランクされる可能性が高くなります。競合他社も同様の地位を占める可能性があります。Google はすでに、多数の劣った候補をインデックスから除外しています。
Google は、その成果に誇りを持っています。96% の文書がインデックスに登録されていないため、人間には明らかでも機械には識別が難しい問題もあります。
私は、Googleがどの認識に優れているかという結論に至った事例を観察してきました。 ページ 技術的な観点からは「良い」か「悪い」かは分かるが、 良いコンテンツ そして 素晴らしいコンテンツ.
Google は、司法省の反トラスト法の証拠として提出された文書でもこれを認めています。2016 年のプレゼンテーションでは、「私たちは文書を理解しているのではなく、シミュレートしているのです」と述べています。
エリック・レーマンがまとめた検索部門全員参加プレゼンテーションのスライド
Google は SERP ユーザーインタラクションを利用してコンテンツ品質を評価しています
Google は従来、ドキュメント コンテンツの品質を評価するために、検索エンジン結果ページ (SERP) でのユーザー インタラクションに依存してきました。その後の Google プレゼンテーションで説明されているように、「各検索者は過去のユーザーの応答から恩恵を受け、将来のユーザーに役立つ応答を提供します。」
リーマンがまとめたSearch All Handsのプレゼンテーションのスライド
Google がコンテンツ品質を判断するためにインタラクション データを使用するかどうかについては、議論が続いています。Google は、コンテンツ品質に関する判断を行うために、ウェブサイトではなく SERP からのインタラクションを主に使用し、直帰率などのサイトベースの指標を排除しているというのが私の考えです。
知識豊富な情報源を注意深く観察すると、Google はコンテンツのランキングにクリック データを採用していることについて非常に透明性が高いことがわかります。
2016 年、Google エンジニアの Paul Haahr 氏は SMX West で「Google の仕組み: Google ランキング エンジニアのストーリー」と題したプレゼンテーションを行いました。Haahr 氏は Google の SERP と、検索エンジンがクリック パターンの変化を精査する方法について説明しました。同氏は、このユーザー データは「予想以上に理解が複雑」であることを認めました。
Haahr 氏の声明は、司法省の証拠物に含まれる「研究のためのランキング」プレゼンテーション スライドにまとめられています。
DOJ の「研究のためのランキング」展示のスライド
Google がユーザー データを解釈し、それを実用的な洞察に変換する能力は、変化する変数とそれに対応する結果との間の因果関係を識別することにかかっています。
SERP は、Google が一般的な変数を理解するための主要なドメインを表します。Web サイト上のインタラクションは、Google の範囲を超えた多数の変数をもたらします。
たとえ Google がウェブサイト上のインタラクションを識別して定量化できたとしても (コンテンツの品質を評価するよりも難しいと言えます)、意味のある推論を行うためにそれぞれ最低限のトラフィックしきい値を必要とする、異なる変数セットが大量に発生することになります。
Google は、その文書の中で、SERP に関して「UX の複雑さが増すにつれて、フィードバックを正確な価値判断に変換することが次第に困難になっている」と指摘しています。
ブランドとバーチャル泥沼
Google は、SERP とユーザー間の相互作用が、文書理解を「シミュレート」する能力の背後にある「核となる謎」を形成すると主張しています。
DOJ の「ログ記録とランキング」展示のスライド
DOJ の展示物によって提供された洞察とは別に、Google がランキングでユーザー インタラクションをどのように利用しているかについての手がかりは、同社の特許の中に見つかります。
特に興味深いのは、「サイト品質スコア」です。これは次のような関係性を検査します。
- 検索者がブランド/ナビゲーション用語をクエリに含めたり、Web サイトがそれらをアンカーに組み込んだりする例。たとえば、「seo news」ではなく「seo news searchengineland」の検索クエリまたはリンク アンカーなどです。
- ユーザーが SERP から特定の結果を選択する傾向がある場合。
これらの指標は、サイトがクエリに対して非常に関連性の高い回答であることを示している可能性があります。品質を評価するこの方法は、「ブランドはソリューションを提供する」というエリック・シュミットの主張と一致しています。
この理論は、ユーザーがブランドに対して強い偏見を持っていることを示す研究結果と一致しています。
たとえば、Red C の調査によると、パーティードレスの買い物やクルーズ旅行の計画などのタスクでは、参加者の 82% が SERP ランキングに関係なく、馴染みのあるブランドを選択しました。
ブランドと、それが生み出す関連する想起を確立するにはコストがかかります。したがって、Google が検索結果のランキング付けにブランドを頼るのは理にかなっています。
GoogleによるAIスパムの識別
Google は今年、人工知能によって作成されたコンテンツに関するアドバイスを発表しました。そのスパム規制では、「スパム的な自動生成コンテンツ」を、主に検索ランキングを操作するために作成されたコンテンツとして明確に定義しています。
Googleからのスパムに関する規制
Google では、スパムは「品質やユーザー エクスペリエンスを考慮せずに自動プロセスで作成されたテキスト」と定義されています。私の解釈では、これは AI システムを使用して、人間による品質保証プロセスなしでコンテンツを生成するすべての人を指します。
AI システムが機密データや個人データでトレーニングされる状況も考えられます。エラーや不正確さを減らすために、より予測可能な結果を生成するようにプログラムされている可能性があります。これは事前の品質保証であると主張する人もいるかもしれません。これはあまり頻繁に利用されない戦略である可能性があります。
それ以外の場合は「スパム」と呼ぶことにします。
以前は、この種のスパムを作成できるのは、データを抽出したり、madLibbing 用のデータベースを構築したり、PHP を使用してマルコフ連鎖を利用してテキストを生成したりできる技術的専門知識を持つ個人に限られていました。
ChatGPT は、いくつかのプロンプトとシンプルな API とともに、OpenAI の緩く強制された公開ポリシーを使用してスパムを民主化しました。このポリシーでは、次のことが規定されています。
「AI がコンテンツの形成に関与していることは、どの読者も簡単には見逃せない方法で明白に開示されており、一般的な読者であれば十分に理解できるだろう。」
OpenAI の出版ポリシー
インターネット上で流通している AI 生成コンテンツの量は膨大です。「regenerate response -chatgpt -results」で Google 検索を行うと、AI 生成コンテンツが「手動で」(つまり、API を使用せずに) 作成された数万ページが見つかります。
多くの場合、品質保証が標準以下であったため、「作成者」はコピー アンド ペースト操作中に ChatGPT の古いバージョンからの「再生成応答」を残しました。
AI コンテンツでスパムとみなされるパターン
GPT-3 が登場したとき、私は Google が編集されていない AI 生成コンテンツにどのように反応するかに興味をそそられ、最初のテスト Web サイトを立ち上げました。
起こったことは次のとおりです。
- 新しいドメインを取得し、基本的な WordPress インストールを構成しました。
- Steam で売れている上位 10,000 のゲームに関する情報をスクレイピングしました。
- これらのゲームを AlsoAsked API に入力して、それらに関して発生したクエリを抽出しました。
- GPT-3 を使用してこれらの質問に対する回答を作成しました。
- 各質問と回答に対して FAQPage スキーマを作成しました。
- ページに埋め込むために、ゲームに関する YouTube ビデオの URL を取得しました。
- WordPress API を利用して各ゲームのページを生成しました。
ウェブサイトには広告やその他の収益を生み出す機能はありませんでした。
全体のプロセスには数時間かかりましたが、人気のビデオ ゲームに関する Q&A コンテンツを含む 10,000 ページの新規 Web サイトが完成しました。
PubCon で Lily Ray が発表したこのウェブサイトの Google Search Console のパフォーマンス データ
実験の結果:
- 約 4 か月後、Google は特定のコンテンツを表示しないことを選択し、その結果、25% のトラフィックが減少しました。
- 1 か月後、Google は Web サイトへのトラフィックの送信を停止しました。
- Bing は期間全体を通じてトラフィックの参照を継続しました。
最も興味をそそられたのは、Google が手動による対策を講じていないようだったことです。Google Search Console には通知がなく、トラフィックが 2 段階減少したことから、手動による介入を疑うようになりました。
私は純粋に AI で生成されたコンテンツでこの傾向を頻繁に観察しました。
- Google にサイトがリストされています。
- トラフィックは毎週着実に増加し、迅速に誘導されます。
- その後、トラフィックはピークに達し、その後急激に減少します。
もう 1 つの例は、Causal.app のシナリオです。この「SEO 強盗」では、競合他社のサイトマップが盗まれ、AI を使用して 1,800 件を超える記事が作成されました。トラフィックは同じ経過をたどり、数か月間増加した後、横ばい状態になり、その後 25% 程度まで減少し、その後クラッシュが発生してほぼすべてのトラフィックが消失しました。
Causal.app の SISTRIX からの可視性データ
SEO コミュニティは、この下落がメディアで大きく取り上げられたことから、手動介入の結果であるかどうかを検討しています。私はアルゴリズムが作用したのではないかと推測しています。
もう一つの魅力的で、おそらくもっと興味深い研究は、LinkedIn の「共同」AI 記事に関するものでした。LinkedIn によって作成されたこれらの AI 生成記事は、事実確認、訂正、補足の形でユーザーに「共同」を促しました。最も積極的な貢献者には、貢献に対して LinkedIn バッジが与えられました。
以前のケースと同様に、トラフィックは急増した後、減少しました。ただし、LinkedIn は一定レベルのトラフィックを維持しました。
LinkedIn /advice/ ページの SISTRIX からの可視性データ
このデータは、トラフィックの変動が手動による介入ではなくアルゴリズムの産物であることを示唆しています。
LinkedIn の共同記事の多くは、人間によって修正されると、Google による価値あるコンテンツの定義に一致するように見えました。しかし、そうではないと判断された記事もありました。
この場合、おそらく Google の判断は正しかったでしょう。
スパムとみなされるのに、なぜランキングされるのでしょうか?
私が観察したところによると、Google ではランキングは複数の段階から成るプロセスです。時間、コスト、データ アクセス可能性などの制約により、より複雑なシステムの実装が妨げられます。
ドキュメントは継続的に評価されていますが、Google のシステムが低品質のコンテンツを識別するまでには時間がかかるのではないかと思います。これが、コンテンツが最初の評価に合格しても、後で基準を満たしていないと識別されるという、繰り返し発生するパターンを説明しています。
この主張を裏付ける証拠をいくつか検証してみましょう。この講演の前半で、Google の「サイト品質」特許と、同社がユーザー インタラクション データを活用してランキング スコアを策定する方法について簡単に触れました。
新しく公開されたサイトの場合、ユーザーは SERP 上のコンテンツに興味を持っていません。そのため、Google はコンテンツの品質を評価できません。
サイト品質の予測に関する別の特許がこのシナリオに対処しています。
もう一度、簡単に言えば、新しいサイトで識別されたさまざまなフレーズの相対的な頻度測定値を最初に取得することによって、新しいサイトの品質スコアが予測されます。
これらの測定値は、以前に評価されたサイトから確立された品質スコアから導出された、以前に確立されたフレーズ モデルを使用して相関付けられます。
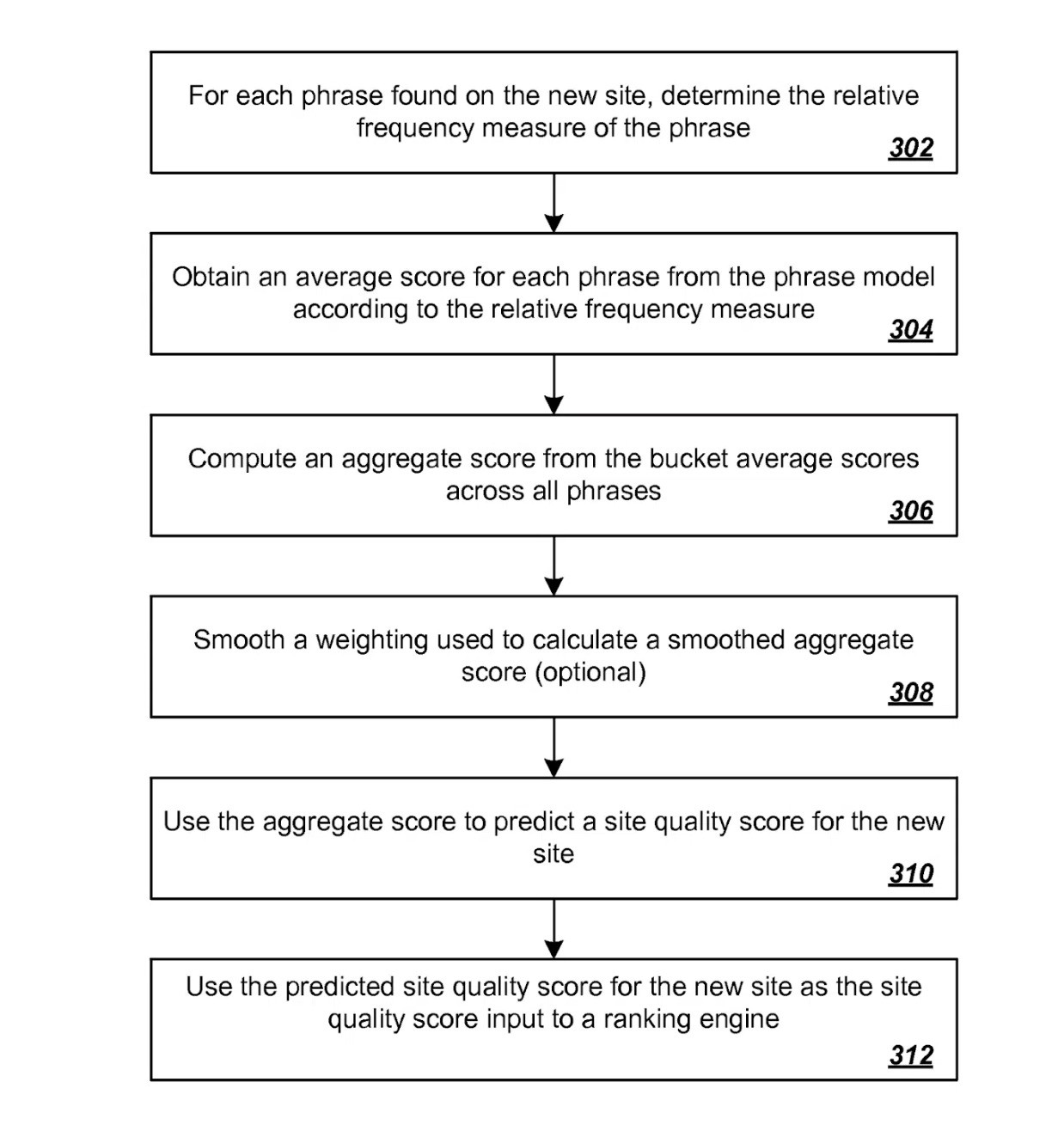
サイト品質予測の特許
Google がまだこのアプローチを採用している場合 (少なくともある程度は採用していると思います)、それは、多数の新しい Web サイトが最初にアルゴリズムに含まれる品質の推定に基づいてランク付けされることを意味します。その後、ユーザー インタラクション データに基づいてランク付けが調整されます。
私と数人の仲間は、Google が予備評価段階でサイトのランキングを上げることがあることに気づきました。
当時の私たちの仮説は、ユーザー インタラクションが Google の予測と一致しているかどうかを判断するための評価が行われたというものでした。一致していない場合、トラフィックは急増したのと同じ速さで減少します。ただし、パフォーマンスが良好であれば、サイトは SERP で適切な位置を維持します。
Google の特許のいくつかは「暗黙のユーザー フィードバック」に言及しており、次のような率直な記述も含まれています。
「ランキング サブシステムには、暗黙のユーザー フィードバックを利用して検索結果の並べ替えをトリガーし、ユーザーに提示される最終ランキングを向上させるランク変更エンジンを含めることができます。」
AJ Kohn 氏は 2015 年にこの種のデータについて詳細に説明しました。
これは数ある特許の中でも古いものであることに注意することが重要です。公開されて以来、Google は次のような数多くの新しいソリューションを考案してきました。
- RankBrain は、Google の「新しい」クエリを処理することで特に注目されています。
- SpamBrain は、ウェブスパム対策として Google が開発した主要ツールです。
Google: ギャップに注意
Google で直接エンジニアリングの知識を持つ者を除いて、外部の者にとって、全体的な SERP とは別に、Google によって個々のサイトでユーザー/SERP インタラクション データがどの程度活用されるかは不明です。
ただし、RankBrain のような最新のシステムは、ユーザーのクリック データに基づいて部分的にトレーニングされていることが知られています。
これらの新しいシステムに関する司法省の証言をAJコーン氏が分析した際、ある点が私の注目を集めました。彼は次のように述べています。
「参考文献によると、一連の文書が「緑のリング」から「青のリング」に移動されています。これらの参考文献は、私がまだ見つけていない文書に関するものです。しかし、証言に基づくと、Google が大規模なセットから、さらにランキング要素を適用できる小規模なセットに結果をフィルタリングする方法を示しているようです。」
これは私の理論と一致しています。Web サイトがテストに合格すると、精度を高めるために、より高度な処理のために別の「リング」に移行します。
現状では次のようになります:
- Google の既存のランキング システムは、AI が生成したコンテンツの制作と公開のペースに追いつくのに苦労しています。
- Gen-AI システムは、文法的に正しく、ほぼ一貫性のあるコンテンツを生成し、Google の初期テストに合格し、さらなる評価が実施されるまでランク付けされます。
ここに問題があります。生成型 AI によるコンテンツの継続的な生成は、Google の初期評価を待つサイトのキューが終わりがないことを意味します。
HCU は UGC を介した GPT に対する解決策となるでしょうか?
Google は、これを克服しなければならない重大な課題として認識しているのではないかと思います。推測ですが、この脆弱性に対処するために、Helpful Content Update (HCU) などの最近のアップデートが実装された可能性があります。
HCU と「隠れた宝石」システムが Reddit のようなユーザー生成コンテンツ (UGC) プラットフォームに利益をもたらしていることは知られています。
すでに多くの訪問者がいるサイトである Reddit は、最近の Google の変更により、他のサイトを犠牲にして検索での可視性が 2 倍以上に増加しました。
私の理論では、いくつかの例外を除き、UGC プラットフォームはコンテンツのモデレーションにより、大量生産された AI コンテンツのソースとなる可能性は低いです。
完璧な検索結果ではありませんが、生の UGC を閲覧することの全体的な満足度は、ChatGPT がオンラインで生成するものを一貫してランク付けする Google を上回る可能性があります。
Google が AI のスパムに迅速に対抗するのに苦労している中、UGC に重点を置くことは、品質を高めるための一時的な対策となる可能性があります。
Google は長期的に AI スパムにどのように対処するのでしょうか?
DOJ の裁判中、Google に関する証言の多くは、検索品質とランキングに重点を置いたソフトウェア エンジニアとして Google で 17 年間勤務した元従業員、エリック レーマン氏によるものでした。
リーマン氏の主張で繰り返し取り上げられたテーマは、Google の機械学習システムである BERT と MUM の重要性がユーザーデータを上回るようになったという点です。これらのシステムは非常に強力になっており、Google は将来、ユーザーデータよりもこれらのシステムに依存するようになるかもしれません。
検索エンジンは、ユーザー インタラクション データの断片を使用して、意思決定のための信頼できる代理データを持っています。課題は、変化に対応するために十分なデータを迅速に収集することにあります。そのため、一部のシステムでは代替方法が組み込まれています。
Google が BERT のような画期的な技術を使用してモデルを強化し、初期のコンテンツ分析の精度を大幅に向上させることができれば、ギャップを埋め、スパムの検出とランク付けの解除に必要な時間を大幅に短縮できる可能性があります。
この問題は依然として存在し、悪用される危険性があります。より多くの個人が、手間をかけずに高収益の機会を探すにつれて、Google の弱点を是正するというプレッシャーが強まります。
皮肉なことに、システムが特定の種類のスパムに大規模に対抗する能力を身につけるにつれて、そのような活動に従事する機会や動機が減少し、システムがほぼ不要になる可能性があります。
