

AI 產生的大量內容的激增給 Google 識別垃圾郵件帶來了挑戰。
AI 產生的內容的存在也使 Google 對內容品質的評估變得複雜。
儘管如此,有跡象表明 Google 正在增強自動檢測 AI 產生的低品質內容的能力。
網路上廣泛存在垃圾郵件 AI 內容
不需要 SEO 的專業知識就能認識到產生的 AI 內容在過去一年已經滲透到 Google 搜尋結果中。
在此期間,Google 對 AI 創作內容的立場發生了變化。官方立場已經從將其視為違反準則的垃圾郵件轉變為優先考慮內容品質而不是內容創建方法。
我相信 Google 對品質的重視已融入許多內部 SEO 演示中,倡導 AI 產生的內容策略。毫無疑問,Google 的這種方法提供了足夠的空間來獲得各個組織管理層的批准。
結果是:大量 AI 產生的低品質內容淹沒了網絡,其中一些內容最初出現在該公司的搜尋結果中。
隱藏的低品質內容
「可見網路」僅代表搜尋引擎選擇索引並在搜尋結果中顯示的網路的一小部分。
根據 Google 的 Pandu Nayak 的說法,正如在 Google 反壟斷審判期間的證詞中透露的那樣,儘管在抓取過程中遇到了數萬億份文檔,但 Google 仍然維護著約 4000 億份文檔的索引。
這意味著 Google 僅索引其在網路爬行過程中遇到的 4% 文件(10 兆中的 4000 億)。
Google 聲稱它在 99% 的查詢點擊中過濾掉了垃圾郵件,這表明它已經消除了大部分不值得的內容。
內容的統治和算法的權威
儘管許多 SEO 和經驗豐富的網站管理員持有相反的觀點,但 Google 仍保持其評估內容品質的能力。許多例子都顯示了劣質內容勝過優質內容的情況。
投資內容的信譽良好的公司可能會躋身網路優質內容的頂級行列。競爭對手可能佔據類似的位置。 Google 已經將許多較差的候選者排除在索引之外。
Google 對其所取得的成就感到自豪。由於 96% 文件未進入索引,有些問題對於人類來說是顯而易見的,但對於機器識別來說卻具有挑戰性。
我觀察到的案例會得出這樣的結論:Google 擅長辨識哪些 頁面 從技術角度來看是“好”與“壞”,但很難區分 好內容 和 很棒的內容.
Google 甚至在司法部反壟斷證據中提供的文件中承認了這一點。在 2016 年的一次演示中,它表示:「我們無法理解文件。我們模擬它。
埃里克·萊曼 (Eric Lehman) 整理的搜尋全員簡報中的幻燈片
Google 依賴 SERP 使用者互動來評估內容品質
Google 傳統上依賴使用者與搜尋引擎結果頁面 (SERP) 的互動來衡量文件內容的品質。正如隨後的 Google 演示中所解釋的那樣:“每個搜尋者都從過去用戶的回應中受益……並貢獻有利於未來用戶的回應。”
雷曼兄弟編譯的「Search All Hands」簡報中的幻燈片
關於 Google 使用交互數據來確定內容品質的爭論一直存在。我相信 Google 主要使用 SERP 的交互而不是網站來做出有關內容品質的決策,從而消除了跳出率等基於網站的指標。
如果密切注意知識來源,就會發現 Google 在內容排名中使用點擊資料的情況相當透明。
2016 年,Google 工程師 Paul Haahr 在 SMX West 發表了題為「Google 工作原理:Google 排名工程師的故事」的演講。 Haahr 討論了 Google 的 SERP 以及搜尋引擎如何審查點擊模式的變化。他承認這些用戶數據「比預期更難以理解」。
哈爾的聲明合併在司法部展品中包含的「研究排名」簡報幻燈片中:
司法部「研究排名」展覽中的幻燈片
Google 解釋使用者資料並將其轉化為可行見解的能力取決於辨別變化變數及其對應結果之間的因果關係。
SERP 代表 Google 理解流行變數的主要領域。網站上的互動引入了許多超出 Google 權限範圍的變數。
即使 Google 可以識別和量化網站上的互動(可以說比評估內容品質更具挑戰性),它也會導致大量不同的變數集,每個變數集都需要最低流量閾值才能進行有意義的扣除。
Google 在其文件中指出,有關 SERP 的「不斷增長的使用者體驗複雜性使得回饋逐漸難以轉化為準確的價值判斷」。
品牌與虛擬泥潭
Google 聲稱,SERP 和使用者之間的互動構成了其「模擬」文件理解能力背後的「核心謎團」。
「記錄與排名」司法部展覽中的幻燈片
除了 DOJ 證據提供的見解之外,Google 如何在排名中使用使用者互動的線索還可以在其專利中找到。
一個特別有趣的方面是“網站品質評分”,它檢查以下關係:
- 搜尋者在查詢中包含品牌/導航術語或網站將其納入錨點的情況。例如,搜尋查詢或連結錨點為“seo news searchengineland”而不是“seo news”。
- 當使用者似乎傾向於從 SERP 中選擇特定結果。
這些指示符可能表示某個站點是對查詢的異常相關回應。這種評估品質的方法與埃里克·施密特的“品牌提供解決方案”的主張是一致的。
這項基本原理與顯示用戶對品牌有強烈偏見的研究相符。
例如,根據 Red C 的一項調查,在購買派對禮服或計劃郵輪假期等任務中,82% 的參與者選擇了熟悉的品牌,無論其 SERP 排名如何。
品牌及其產生的相關召回的建立成本高。因此,Google 依靠它們對搜尋結果進行排名是合乎邏輯的。
根據Google識別AI垃圾郵件
Google 在今年發布了有關人工智慧創作內容的建議。其垃圾郵件法規明確將「自動產生的垃圾郵件內容」描述為主要為了操縱搜尋排名而產生的內容。
關於 Google 垃圾郵件的規定
Google 將垃圾郵件定義為「透過自動化流程建立的文本,不考慮品質或使用者體驗」。在我的解釋中,這是指任何使用 AI 系統在沒有人工品質保證流程的情況下產生內容的人。
在某些情況下,AI 系統可能會接受機密或私人資料的訓練。它可以被編程為產生更可預測的結果,以減少錯誤和不準確。有人可能會說這是事先的品質保證。這可能是一種不常使用的策略。
我將所有其他情況稱為“垃圾郵件”。
以前,只有具備提取資料、為 madLibbing 建立資料庫或使用 PHP 利用馬可夫鏈生成文字的技術專業知識的個人才能產生此類垃圾郵件。
ChatGPT 透過一些提示和簡單的 API 實現了垃圾郵件的民主化,以及 OpenAI 鬆散執行的發布策略,該策略指定:
“AI 參與塑造內容的方式被公開披露,任何讀者都無法輕易忽視,而且一般讀者也能充分理解。”
OpenAI 的出版政策
AI 產生的內容在網路上傳播的數量龐大。 Google 搜尋「重新產生回應 -chatgpt -results」會顯示數萬個頁面,其中包含「手動」(即不使用 API)製作的 AI 產生的內容。
在許多情況下,品質保證非常不合格,以至於「作者」在複製和貼上操作期間留下了舊版本 ChatGPT 的「重新產生回應」。
在 AI 內容中觀察到的被視為垃圾郵件的模式
當 GPT-3 出現時,我對 Google 如何回應未經編輯的 AI 產生的內容很感興趣,因此我建立了最初的測試網站。
這就是發生的事情:
- 取得了一個新網域並配置了基本的 WordPress 安裝。
- 抓取了 Steam 上銷量最高的 10,000 款遊戲的資訊。
- 將這些遊戲輸入 AlsoAsked API 以提取有關它們的查詢。
- 使用 GPT-3 來回答這些問題。
- 為每個問題和回應制定了 FAQPage 架構。
- 檢索了有關該遊戲的 YouTube 影片的 URL,以便嵌入到頁面上。
- 利用 WordPress API 為每個遊戲產生一個頁面。
網站上沒有廣告或其他創收功能。
整個過程花了幾個小時,我有了一個新的 10,000 頁的網站,其中有一些與流行視頻遊戲相關的問答內容。
Lily Ray 在 PubCon 上展示的來自 Google Search Console 的本網站效能數據
實驗結果:
- 大約4個月後,Google選擇不顯示某些內容,導致25%流量下降。
- 一個月後,Google 停止將流量引導至該網站。
- 必應在整個期間繼續引用流量。
什麼最讓我感興趣? Google似乎沒有採取手動動作。 Google Search Console 中沒有任何通知,兩步驟的流量遺失讓我懷疑是否有人工幹擾。
我經常透過純粹 AI 產生的內容觀察到這種趨勢:
- Google 列出了該站點。
- 流量得到快速引導,並逐週持續成長。
- 然後流量達到峰值,隨後迅速下降。
另一個例子是Causal.app的場景。在這次「SEO 搶劫」中,競爭對手的網站地圖被清除,並使用 AI 撰寫了 1,800 多篇文章。流量也遵循同樣的路線,在穩定增長之前持續了幾個月,然後下降了約 25%,隨後發生了一場幾乎消滅了所有流量的事故。
來自 SISTRIX for Causal.app 的可見性數據
由於吸引了大量媒體報導,SEO 社區正在考慮這種下降是否是人工幹預的結果。我推測是演算法在起作用。
另一項引人入勝、也許更有趣的研究涉及 LinkedIn 的「協作」AI 文章。這些由 LinkedIn 製作的 AI 生成的文章鼓勵用戶以事實檢查、更正和補充的形式進行「協作」。最活躍的貢獻者將因其貢獻而獲得 LinkedIn 徽章。
與之前的案例一樣,流量激增然後消退。然而,LinkedIn 保持了一定的流量水平。
來自 SISTRIX 的 LinkedIn /advice/ 頁面的可見性數據
此數據顯示流量波動是演算法的產物,而不是人工幹擾。
經過人工修改後,許多 LinkedIn 協作文章似乎符合 Google 的有價值內容的定義。然而,其他人卻有不同的看法。
也許Google在這種情況下的判斷是正確的。
如果它被認為是垃圾郵件,為什麼它會獲得排名?
據我觀察,Google 的排名是一個多階段的過程。時間、成本和資料可存取性等限制阻礙了更複雜系統的實施。
儘管不斷評估文檔,但我懷疑 Google 的系統識別低品質內容之前存在延遲。這解釋了反覆出現的模式:內容通過了初步評估,但後來才被確定為不合格。
讓我們檢視一下支持這一論點的一些證據。在本次演講的前面,我們簡要地提到了 Google 的「網站品質」專利以及他們如何利用用戶互動數據來製定排名分數。
對於新推出的網站,使用者還沒有參與 SERP 上的內容。因此,Google 無法評估內容的品質。
另一項與預測站點品質相關的專利解決了這種情況。
再次,用過於簡單的術語來說,透過最初獲得新網站上識別的各種短語的相對頻率測量來預測新網站的品質分數。
然後使用先前建立的短語模型將這些測量結果相關聯,該短語模型源自先前評級網站建立的品質分數。
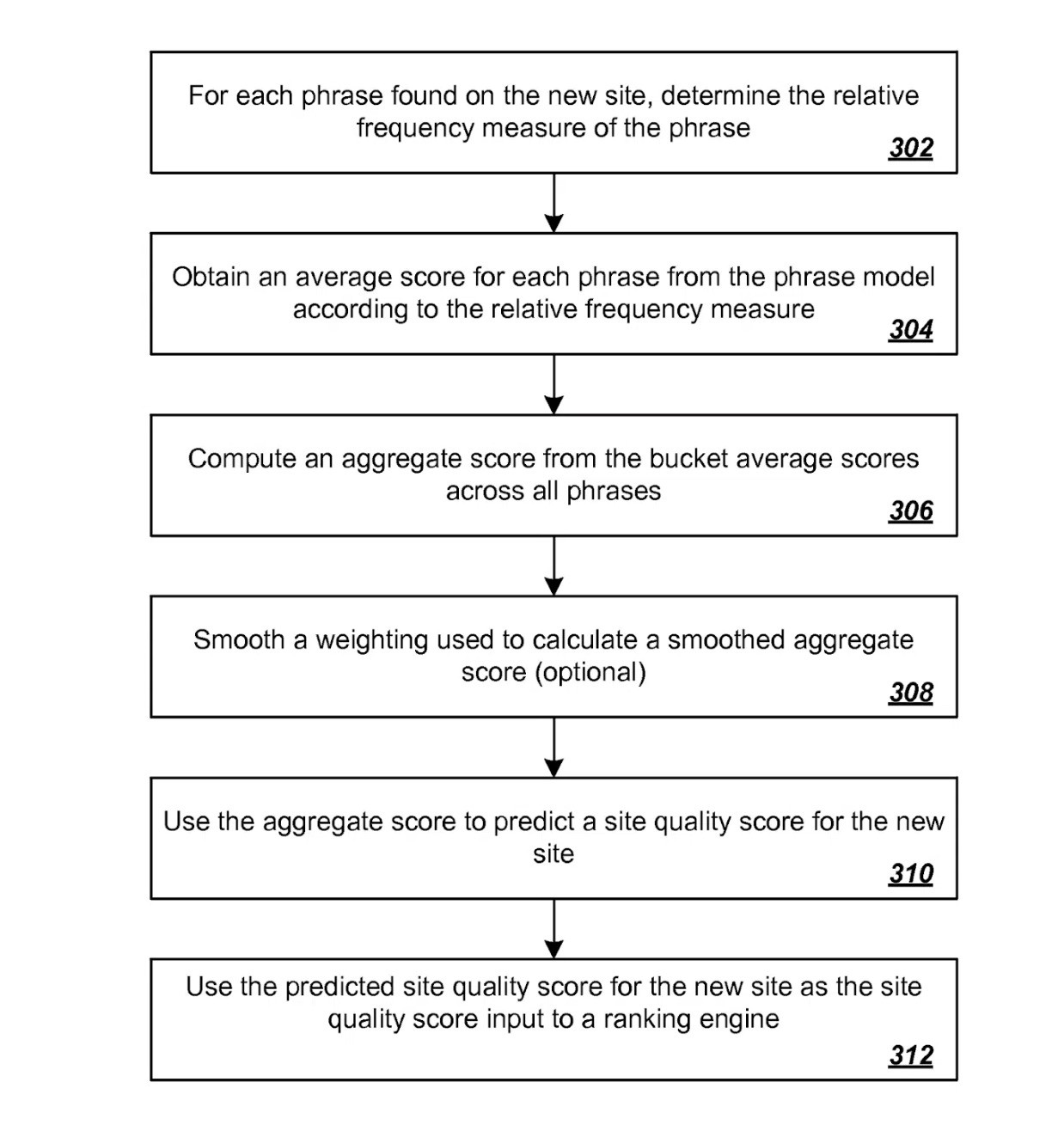
預測站點品質專利
如果 Google 仍在採用這種方法(我相信至少在某種程度上是這樣),則意味著許多新網站最初是根據演算法中包含的品質估計進行排名的。隨後,排名會根據用戶互動數據進行細化。
我和幾個同伴注意到,Google 有時會提升初步評估階段網站的排名。
我們當時的假設是進行評估以確定使用者互動是否與 Google 的預測一致。如果不是這樣,交通量的減少和激增的速度一樣快。然而,如果表現良好,該網站在 SERP 中保持著不錯的位置。
Google 的多項專利引用了“隱式用戶回饋”,包括以下直截了當的聲明:
“排名子系統可以包含排名修改器引擎,該引擎利用隱式用戶反饋來觸發搜尋結果的重新排序,以增強呈現給用戶的最終排名。”
AJ Kohn 早在 2015 年就詳細介紹了此類數據。
值得注意的是,這是眾多專利中較老的專利。自發布以來,Google 設計了許多新的解決方案,例如:
- RankBrain,明確指出用於處理 Google 的「新」查詢。
- SpamBrain,Google 的主要打擊網路垃圾郵件的工具。
Google:注意間隙
除了整體 SERP 之外,外界不清楚 Google 在各個站點上會利用多少用戶/SERP 交互數據,除了那些在 Google 具有直接工程知識的人之外。
然而,眾所周知,像 RankBrain 這樣的現代系統是部分基於使用者點擊資料進行訓練的。
AJ Kohn 對 DOJ 關於這些新系統的證詞的分析中的一個具體點引起了我的注意。他提到了:
「參考文獻顯示將一組文件從『綠環』移至『藍環』。這些參考文獻涉及我尚未找到的文件。然而,根據證詞,它似乎說明了 Google 如何將結果從大集合過濾到可以應用進一步排名因素的較小集合。
這與我的理論相符。如果一個網站通過了測試,它就會轉移到另一個「環」進行更高級的處理,以提高準確性。
就目前情況而言:
- Google 現有的排名系統很難跟上 AI 產生的內容製作和發布的步伐。
- Gen-AI 系統產生語法正確且基本連貫的內容,通過 Google 的初始測試和排名,直到進行進一步評估。
問題就在這裡:使用生成式 AI 不斷產生內容意味著有一個永無止境的網站佇列等待 Google 的初始評估。
HCU 是透過 UGC 對抗 GPT 的解決方案嗎?
我懷疑 Google 承認這是他們必須克服的重大挑戰。據推測,最近的更新(例如有用內容更新(HCU))可能已被實施來解決此漏洞。
眾所周知,HCU 和「隱藏的寶石」系統使 Reddit 等用戶生成內容 (UGC) 平台受益。
Reddit 是一個訪問量很高的網站,由於最近的 Google 修改,其搜尋可見度增加了一倍多,但犧牲了其他網站的利益。
我的理論是,由於內容審核的原因,UGC 平台(除一些例外)不太可能成為批量生產的 AI 內容的來源。
雖然搜尋結果並不完美,但瀏覽原始 UGC 的整體滿意度可能會超過 Google,無論 ChatGPT 線上產生的內容如何一致排名。
由於 Google 難以迅速打擊 AI 垃圾郵件,因此強調 UGC 可能是提高品質的臨時補救措施。
從長遠來看,Google 將如何應對 AI 垃圾郵件?
在 DOJ 審判期間,有關 Google 的大部分證詞均來自 Eric Lehman,他是一名已工作 17 年的前僱員,曾在 Google 擔任軟體工程師,專注於搜尋品質和排名。
雷曼聲明中反覆出現的主題是 Google 的機器學習系統、BERT 和 MUM 的重要性日益增加,超越了使用者資料。這些系統變得如此強大,以至於 Google 未來可能更依賴它們,而不是用戶資料。
透過使用者互動資料片段,搜尋引擎擁有可靠的決策代理。挑戰在於如何足夠快地收集足夠的數據以跟上變化,這就是為什麼一些系統採用替代方法的原因。
如果 Google 可以使用 BERT 等突破性技術來增強其模型,從而顯著提高初始內容分析的準確性,那麼他們就可以彌補差距,並顯著減少檢測和對垃圾郵件進行排序所需的時間。
這個問題仍然存在,並且很容易被利用。隨著越來越多的人尋找輕鬆、高收益的機會,Google 糾正其弱點的壓力越來越大。
諷刺的是,當一個系統能夠熟練地大規模打擊特定類型的垃圾郵件時,它可能會因為減少參與此類活動的機會和動機而變得幾乎多餘。
